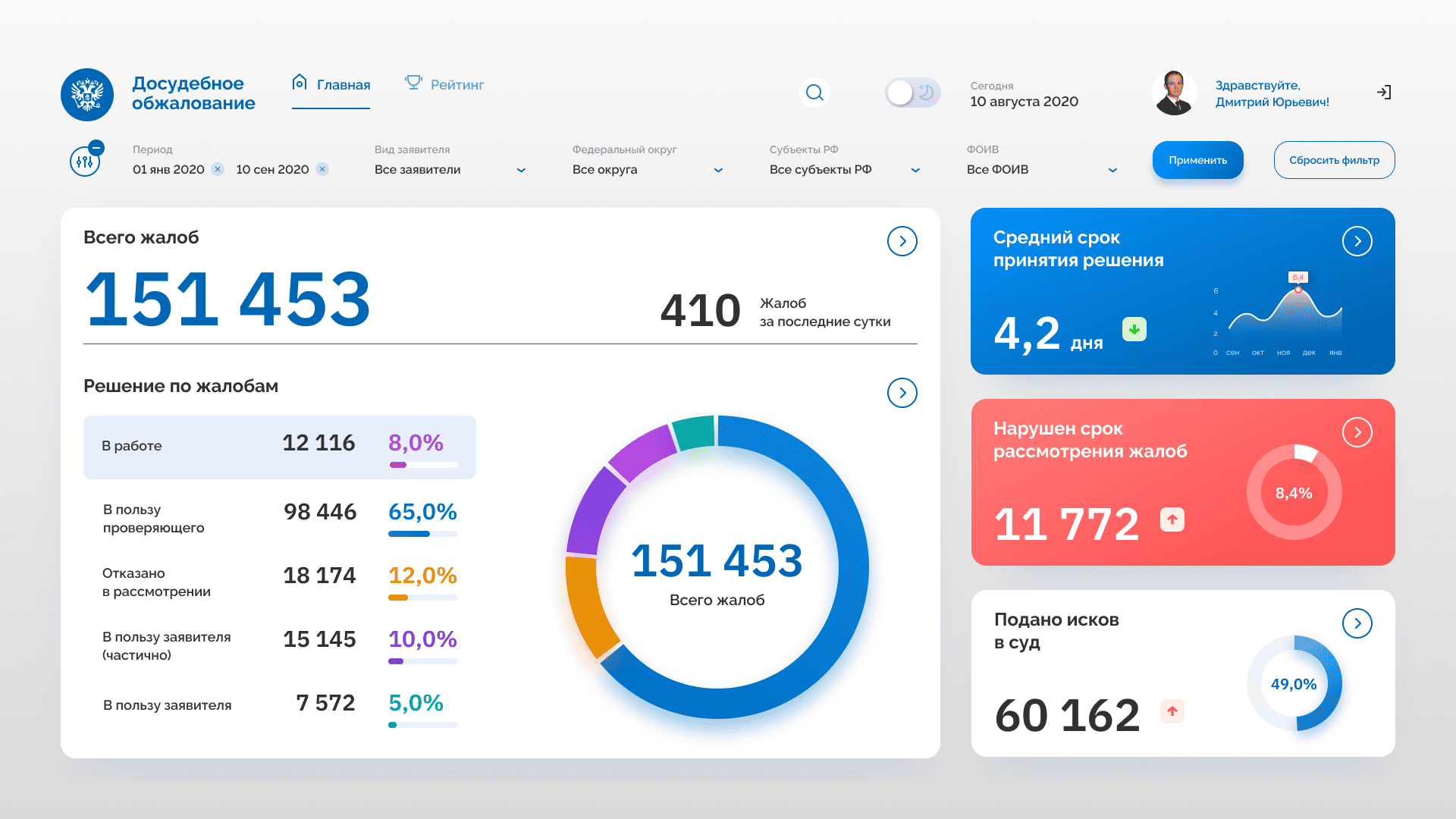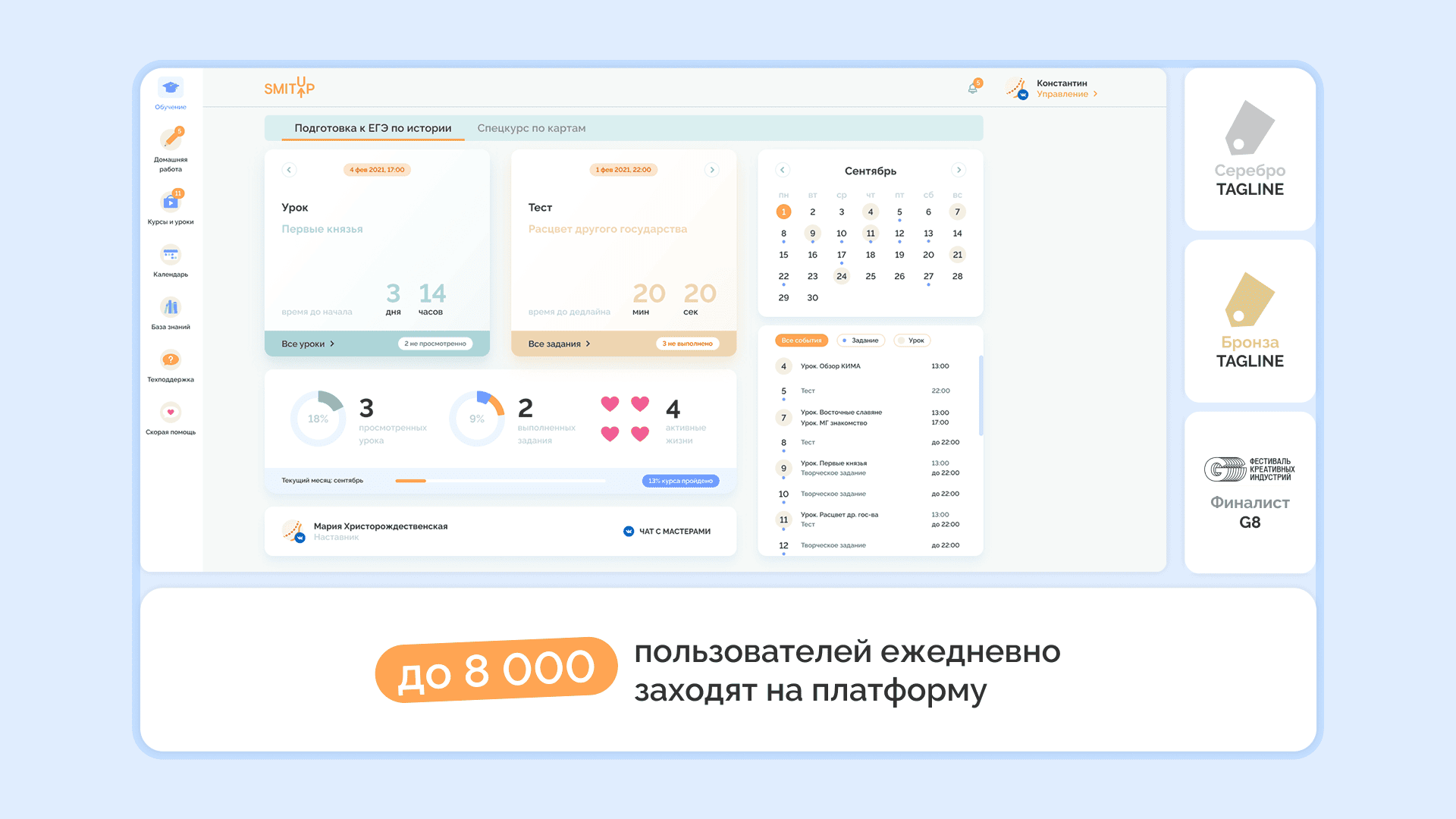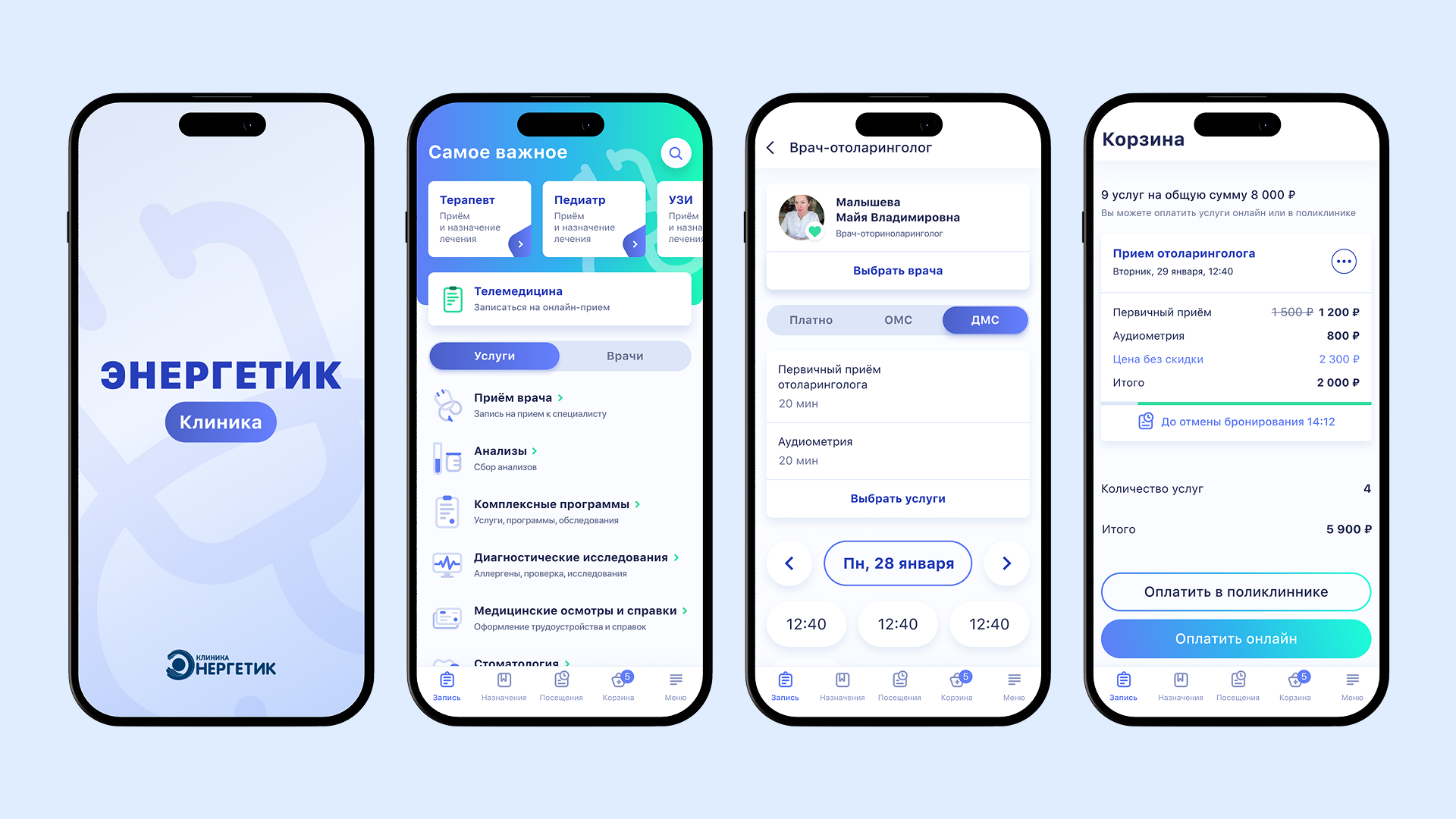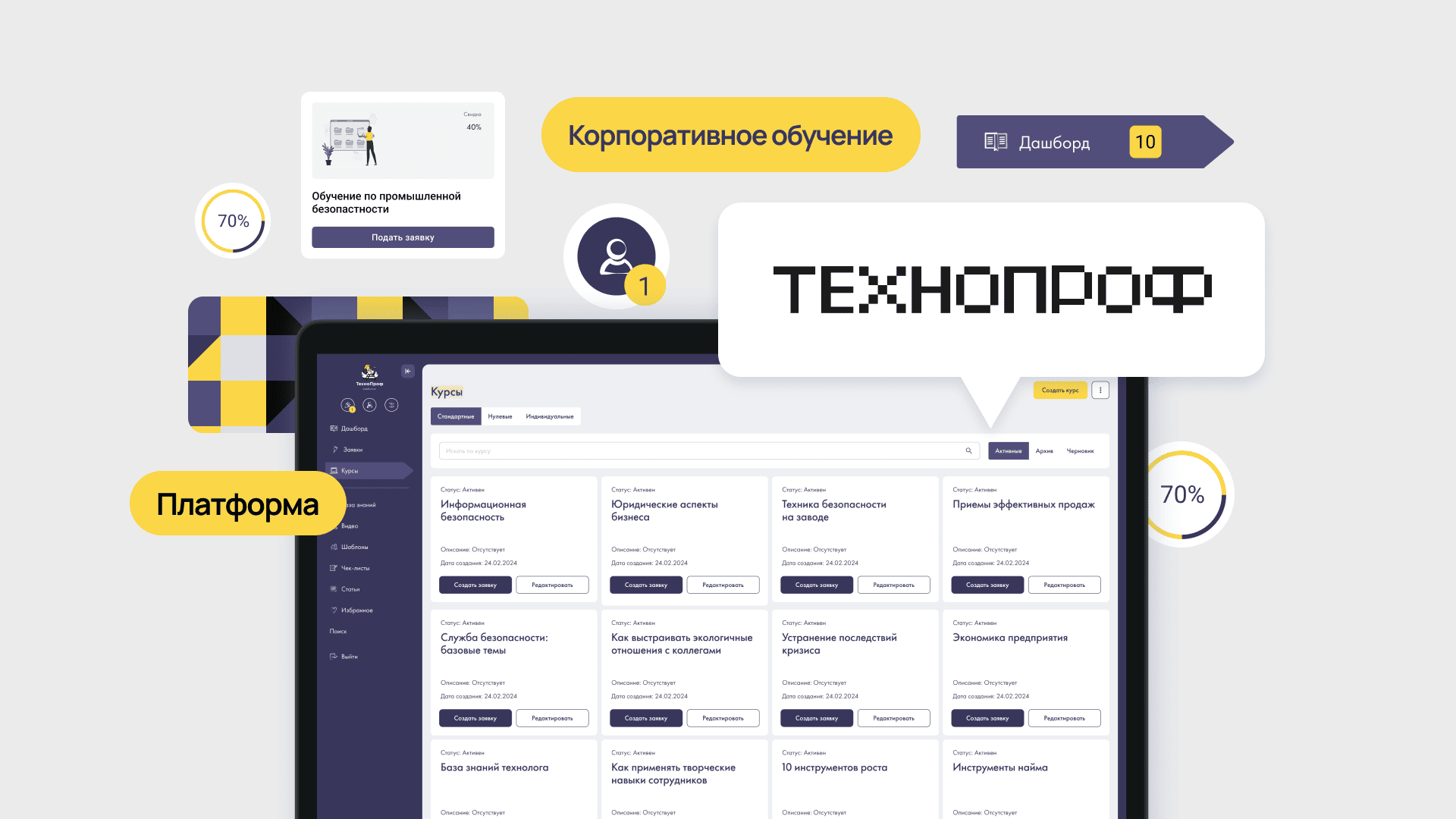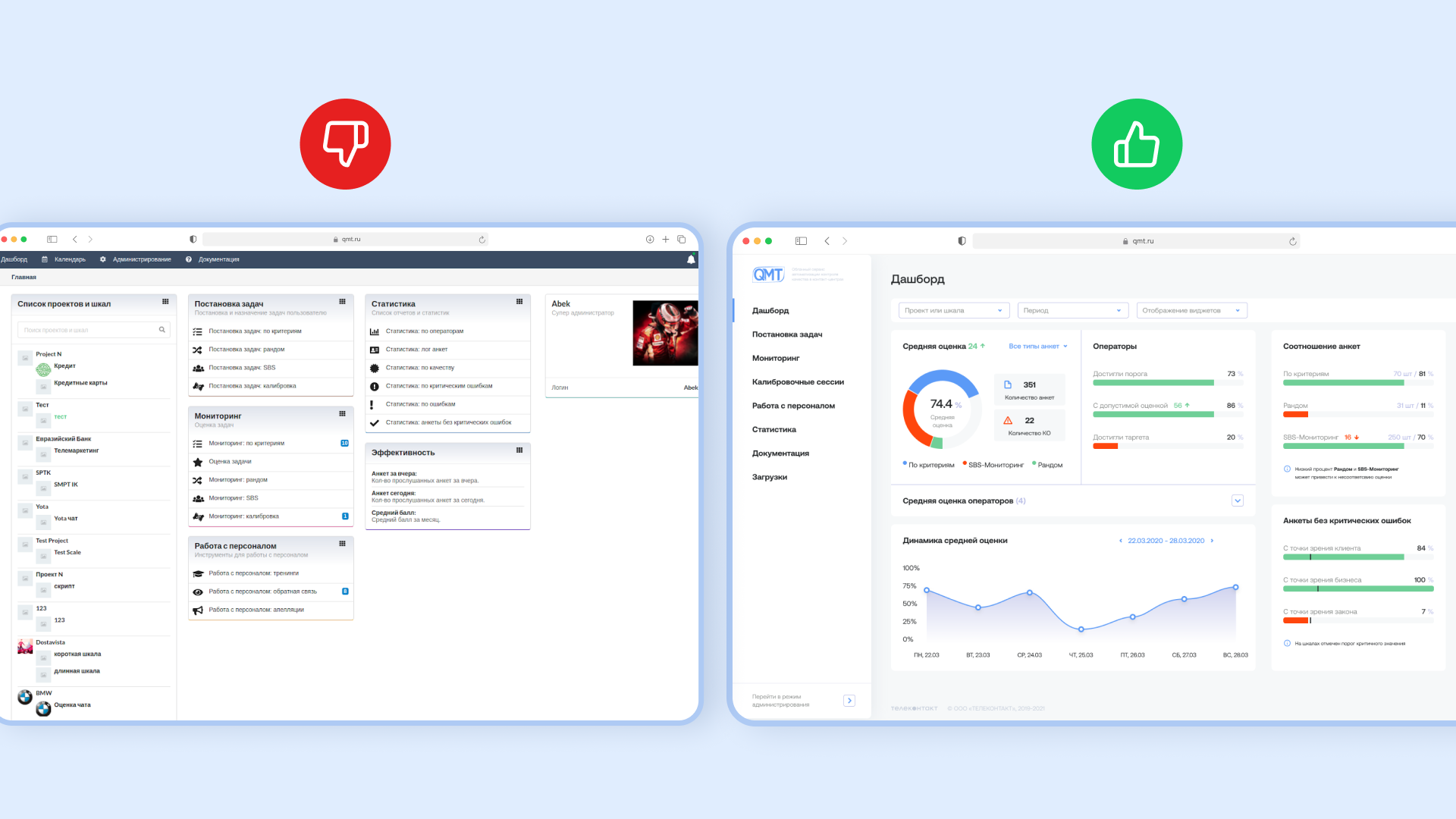
Особенности редизайна веб-продукта и как он помогает избавиться от хаоса в интерфейсе, ускорить работу пользователей и создать масштабируемую систему.

Как тестирование сайтов, приложений и сервисов влияет на скорость разработки, эффективность бизнеса и качество итогового веб-продукта? Рассказываем про цели и этапы тестирования, рассматриваем отличия видов, методов и типов диагностики.

Раскрываем особенности разработки MVP, его виды и преимущества, а также как минимально жизнеспособный продукт может помочь вашему бизнесу.